The classic analogy for SQL indexes goes … databases are like libraries.
Tables are like books stored in a library.
Rows are stored on pages of a book.
Flipping through a textbook page by page looking for that one page you need is going to take time. The same way scanning millions of rows is going be time-consuming and tedious. That’s where SQL indexes come in.
Why do I need an index?
Are there different types of indexes?
Where can I find my index once it’s created?
What are good candidates for indexes?
Can’t I do this later?
Do I need to do this at all?
How many indexes are too many?
Is this the answer to all my performance problems?
Why do I need an index?
Indexes speed up performance by either ordering the data on disk so it’s quicker to find your result or telling the SQL engine where to go to find your data. If you don’t apply an index, the SQL engine will scan through every row one by one.
While this isn’t necessarily a bad thing, as your database grows things could start to slow down.
Are there different types of indexes?
There are two main types in SQL Server:
Clustered index – the contents page
Physically arranges the data on disk in a way that makes it faster to get to.
You can only apply one per table because the data can only be ordered one way.

|
1 2 |
create clustered index [id_idx] on [dbo].[actor_registration](actor_id) |
Non-clustered Index – the index at the back of a book.
These create a lookup that points to where the data is.
You can create up to 999 but as each index carries overhead and maintenance, you’ll probably want to stick to just a few.

|
1 2 |
create nonclustered index [last_name_idx] on [dbo].[actor_registration](last_name) |
Where can I find my index?
You can find the indexes on a table by expanding the table where the index is, then expanding indexes.
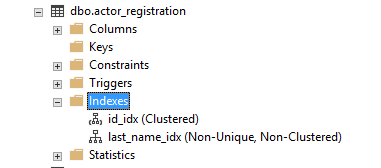
This is also where you can create an index using the wizard. In the example below the option for clustered index is now greyed out because we have one on this table already.
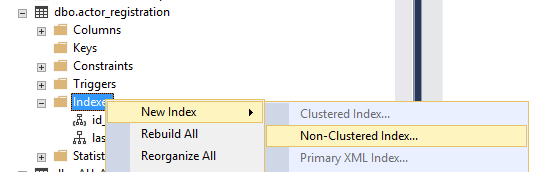
What are good candidates for indexes?
Ideally something unique, sequential and small that you are using in SELECTs and JOINs.
Can’t I do this later?
Sure, no problem.
Sometimes it’s good to get a handle on how you are querying the data and then add them later.
If you have no clustered indexes on your table the data is stored in the order it comes in. This is called Heaped Storage and is effectively an expensive way of storing a spreadsheet.
Be aware indexes take time to apply if your tables are large by the time you get to this task it may take some time.
Do I need to do this at all?
There’s no rule saying you should or shouldn’t. The advantages of not adding indexes are that your INSERTs and UPDATEs will be faster and your database will be physically smaller.
If you do notice things getting slow, check out the execution plan for any suggestions and more information on where the effort is going to execute your query.
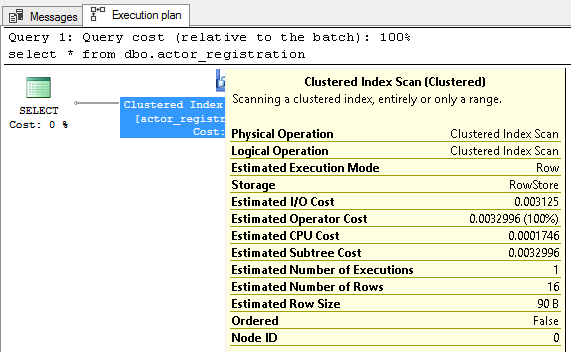
How many indexes are too many?
As always, it depends. Too many indexes may slow down performance. Once you’ve created an index for your primary key and unique keys it will be up to you, the execution plan and perhaps your friendly DBA as to what you do next.
Is this the answer to all my performance problems?
Indexes need maintenance. They may improve performance initially, but need to be reviewed, updated and maintained as your database grows. They aren’t a ‘set and forget’ magic bullet and should be reviewed, and deleted, as your requirements change.
Your best bet at first is to use the execution plan to view its suggestions or ask your friendly DBA to lend a hand.
Photo by Burst from Pexels

Comments are closed, but trackbacks and pingbacks are open.